Copyright Notice:
Users of the open source software Text Narratives Analyzer (TNA) are kindly requested to acknowledge the original authors by citing the following publication:
Park, J., & Arteaga, C. (2023). AI Analyzer for Revealing Insights of Traffic Crashes. NCHRP-IDEA Program Project Final Report. Retrieved from https://trid.trb.org/View/2227519
Overview
TNA (Text Narratives Analyzer) is an open-source tool to find potential correlations between text narratives and a target class or category. For example, TNA finds potential correlations between crash narratives and the fatal or non-fatal classification of the crashes, as illustrated in the image below. TNA works by training a text classifier to predict the target class for a given narrative (e.g., fatal) and using sliding-window and peak-detection strategy to identify phrases correlated with the target class.
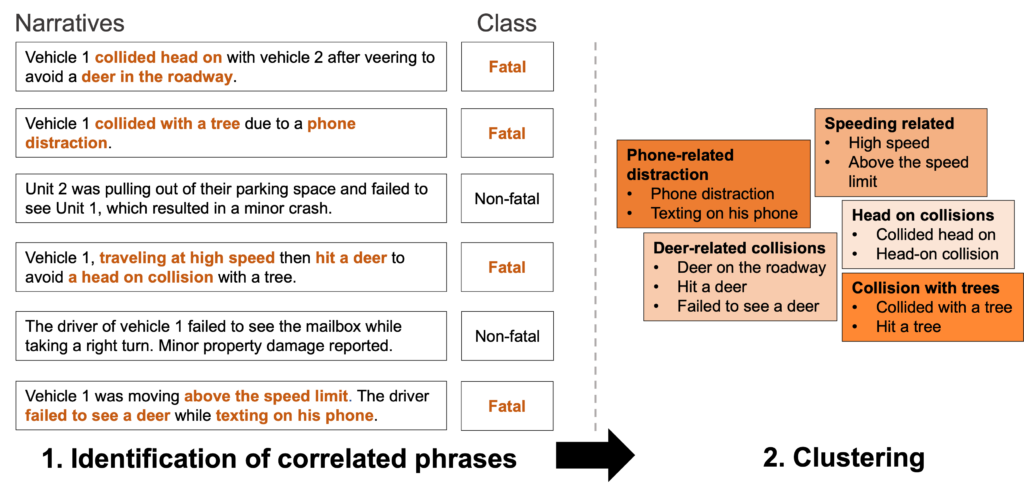
TNA was initially conceived for analysis of crash narratives, but the correlation-finding approach can be applied to other data sources, as shown in the “Tutorial” section, in which a dataset of movie reviews is used for demonstration purposes.
Installation
TNA is a web application that runs on a Python backend. It uses Streamlit for web rendering, PyTorch and HuggingFace Transformers for model training, as well as Pandas, Numpy, and Scikit-Learn for data handling. The steps below install all the required Python dependencies.
TNA can be installed on Windows, Linux, or Mac, as the only dependency is a functional Python environment with support for the aforementioned libraries.
Installation steps
- Download and install Python 3.7 or newer
- Download TNA’s source code and unzip the file.
- Open a command line and navigate to the unzipped folder.
- Install required packages using:
pip install -r requirements.txtHint: TNA works faster on GPUs, as training deep learning models can be performed efficiently on these devices. To use a GPU, make sure you install PyTorch with GPU support by following PyTorch’s installation instructions.
If you have any feedback about the usefulness of tool or want to report any issues, please let us know using this contact form.
Run web application
Open a command line, navigate to the project folder, and execute:
streamlit run web.pyThis will open a new tab in your web browser, as illustrated in the figure below. Alternatively, you can navigate to your localhost URL at the default streamlit’s port 8501.
TNA can be installed locally (on a single computer) or on a server and can be accessed using the IP address of the server and the default port 8501. For troubleshooting of server installation check Streamlit’s instructions to enable remote access.
Tutorial
This tutorial explains how to use TNA to identify potential correlations between phrases in narratives and a target class. This tutorial uses a dataset of narratives for moview reviews whose target class is the movie sentiment (positive or negative). Therefore, TNA will identify phrases in the narratives correlated with positive moview reviews. This dataset is a smaller version of the popular IMDB movie reviews dataset. You can download the dataset from this link.
Follow the steps outlined below, which are also described in detail in the video.
Step 1. Data loading and parameter selection
The tool takes as input a CSV file. As illustrated in the image below, the CSV file must contain a text column (review) and a target column (sentiment) encoded in a binary format (1 for positive class, 0 for negative class). A column with unique ids (id) can be also provided but it is not required. The text data does not need any type of pre-processing.
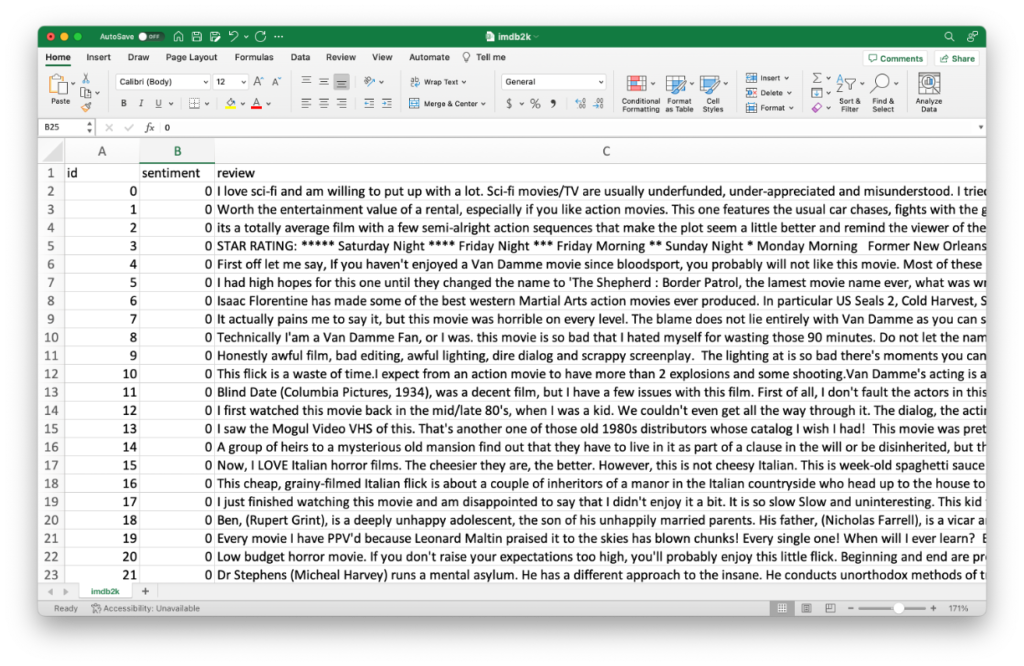
To load the data, click the “Browse files” button and locate the CSV file in your local computer. After uploading the file select 1) the “Narrative column”, which contains the text data and 2) the “Target column”, which contains information for the target class. The system uses information in these two columns to establish correlations between the text narratives and the target class. Also, you need to set the “Number of epochs” to train the underlying text classifier that identifies correlations. You can use “10“ epochs as set by default and change this number later as explained in the next step. Finally, you can also select the “Unique IDs column” to show in the final results the ID of the narratives from which the phrases were extracted.
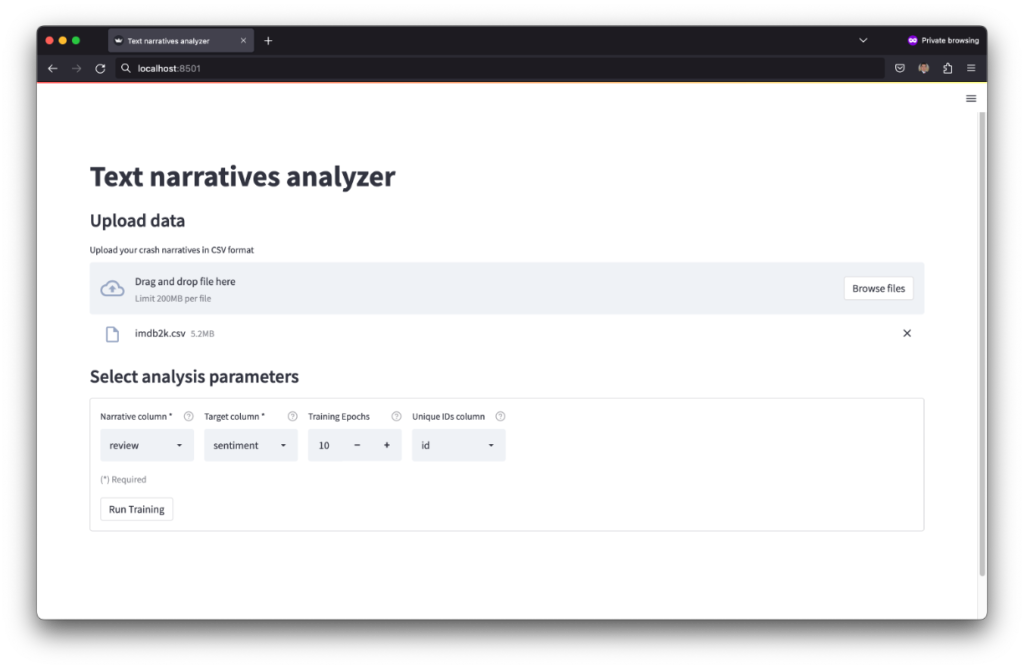
Step 2. Text classifier training
After uploading the data and selecting the analysis parameters you simply need to click the “Run Training” button to train the underlying text classifier that establishes correlations between the narratives and the target column. The training may take a few seconds or several minutes depending on the computer specs (GPUs can make the training faster), the size of the dataset, and the selected number of epochs. After the training is complete, the system shows a “loss plot” and provides instructions on how to interpret this plot to determine whether the training was successful or not. In general terms, you want both the training and evaluation loss to decrease at a similar rate. Over training (a.k.a. over fitting) is a very common scenario, as shown in the image below, in which case you need to reduce the number of epochs and run the training again.
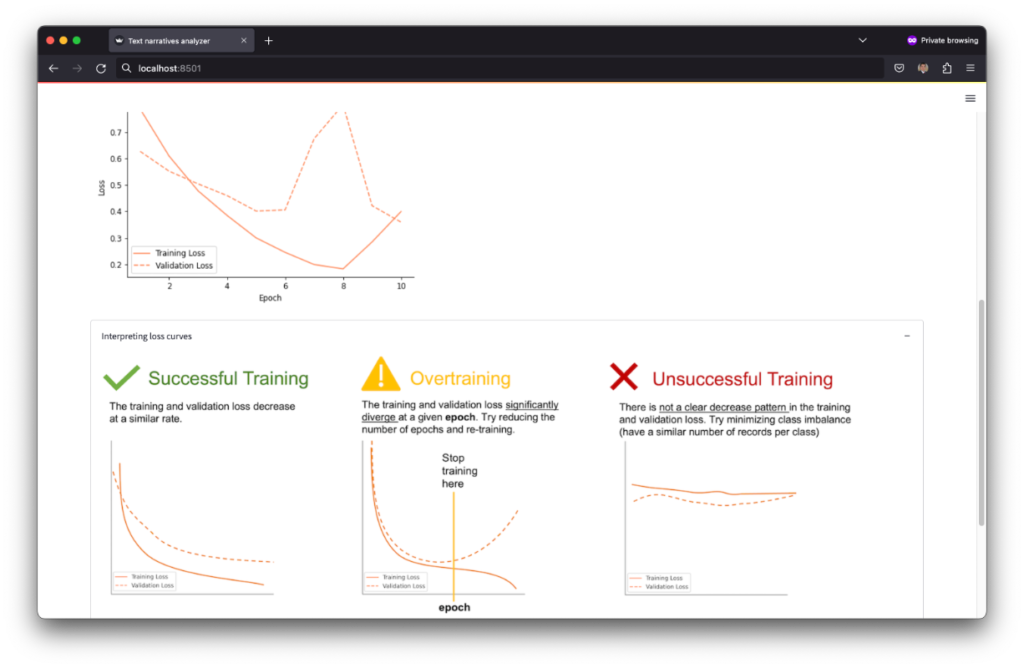
Note that after reducing the number of epochs to 6 (a.k.a early stopping), that the loss plot shows a better decreasing patter for the training and validation loss.
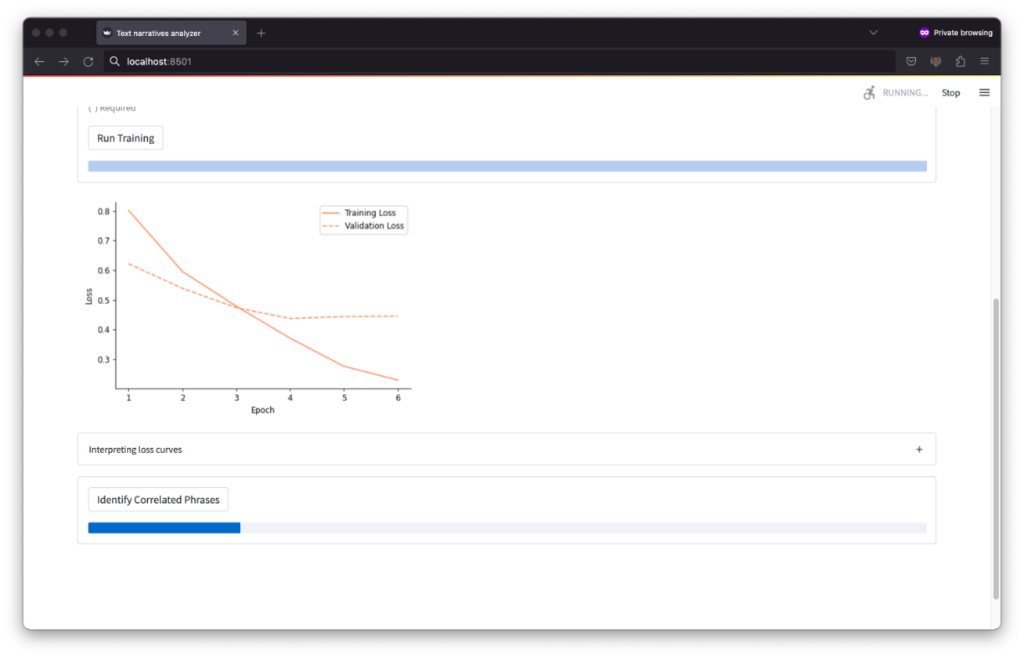
Step 3. Identification and clustering of correlated phrases
Finally, after the training is complete, you just need to click the “Identify phrases” button to execute the sliding-window and peak detection approaches, which extract all the phrases potentially correlated with the target column and cluster such phrases by similarity. The output of the tool is a set of clusters that group similar phrases in the narratives identified as correlated with the output column. The output includes the four most common words on each cluster, the number of phrases within the clusters, and the average correlation of the phrases within that cluster. By default the output shows 15 sample phrases, but provides an option to change the number of phrases to display (top right of the screen).
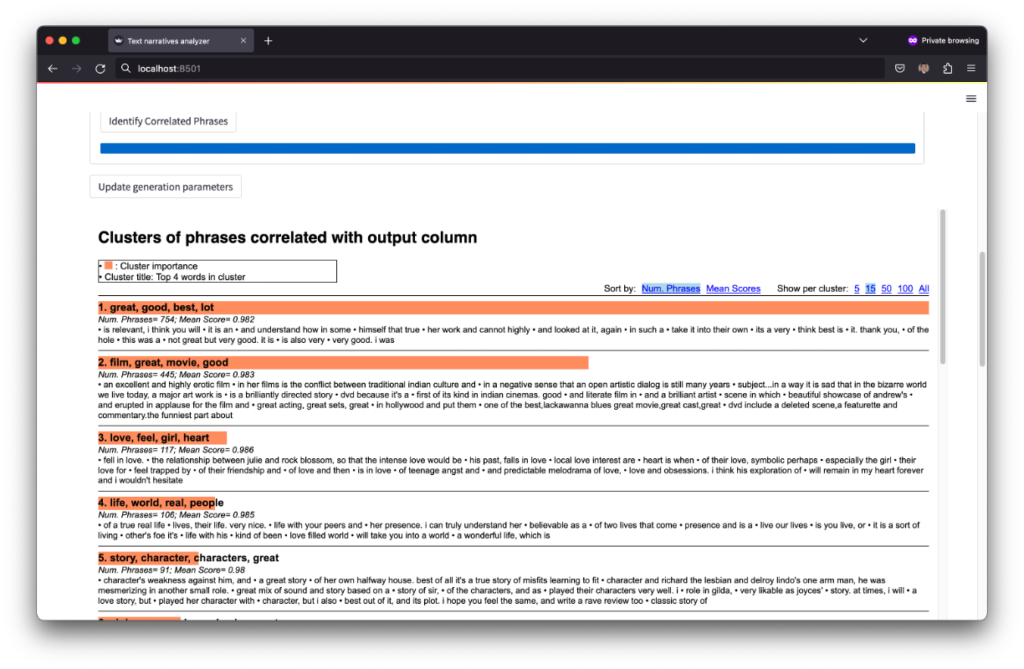
The output shows that the tool identified phrases that describe “great film”, “good movie”, “great story”, “great character” as correlated with positive movie reviews. To better tune the output of the system, you can click the “Update generation parameters” button, which provides options to select a higher or lower threshold for the peak detection algorithm (to define a desired correlation strength) and the number of clusters to be generated.
Analysis of quantitative data
For analysis of quantitative data, this project includes an open-source Python library called xlogit. This library conducts statistical-based analysis (Logit and Multinomial Logit) to identify potential causality associations between a set of factors and a desired target class. For example, for traffic safety analysis xlogit identifies potential causality associations between crash factors and severe crashes. For instructions on how to use xlogit, please follow xlogit’s documentation and examples.
License
TNA is an open-source software released under the GNU General Public License v3.0. This program is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version. This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
Limitations
• Bias prone algorithms: Algorithmic bias can occur when the data used to train the model is biased or when the algorithm itself is biased. This can result in unfair or discriminatory outcomes, such as the model making incorrect assumptions or predictions based on race, gender, or other protected characteristics. For instance, for analysis of crash narratives, the tool may identify phrases describing arbitrary groups from specific gender, race, or background as frequently associated with fatal crashes, so users should exercise caution when interpreting the results and take steps to mitigate potential biases.
• Inherent random-based training and potentially unstable results: The training of the underlying text classifiers used to identify correlations involves random processes, which may result in different results every time the software is used. This is because the training process involves an optimization routine that may take different paths at every execution depending on the initialization of the underlying neural network. This may result in the text classifier paying more or less attention to certain types of phrases for different executions. For instance, for analysis of crash narratives, the text classifier may focus on phrases that describe alcohol-involvement in the crashes, whereas in another execution it may focus on phrases that describe involvement of pedestrians. To mitigate this potential issue, it is recommended to execute the tool multiple times and analyze the results of multiple executions.
• Focus on pure correlations: The tool focuses on finding correlations, but for certain analysis this might cause inconvenient or noisy results. For instance, for analysis of crash narratives, the tool may identify as correlated with severe crashes the phrases that describe people transported to the hospital or involvement of fire departments to help victims. Although these phrases are clearly correlated with fatal crashes, they do not offer any insights on potential crash severity contributors. Therefore, users need to take this into consideration when analyzing the output of the tool.
• Imperfect clustering: Clustering of text phrases is a problem that has no perfect solution up until now. TNA uses a clustering based on deep neural networks for semantic similarity, which is among the most sophisticated existing mechanisms for text clustering. However, the clustering results are still imperfect, and you might find some rare instances of phrases of different nature in the same cluster. This should be rare but still possible.
• The nature of the analysis is more exploratory rather than conclusive. Given that text or linguistic data may carry some ambiguity, it is important to exercise caution when interpreting the results of the tool and avoid using the output of the tool as a single source of decision making.
Acknowledgments
This research was supported by the National Cooperative Highway Research Program (NCHRP) (IDEA Project #231). We thank the Massachusetts Department of Transportation (MassDOT) for providing the data used in this study. All the opinions, findings, and conclusions expressed in this material are those of the authors and do not necessarily reflect the views of the NCHRP or the MassDOT.
Forum
Join the discussion. Please leave your comments, questions, or anything you want to discuss with the user’s forum.